
9 SQL tricks you may not know about
This one's for my SQL-loving friends out there!


Hi friends, hope you all had a great July 4th and that your company didn’t make you work on July 5th!
Welcome back to The Data Diaries. Since the last episode, I announced my first giveaway of 3 free LinkedIn profile audits on Instagram, and I had over 300 people enter 😱
Winners were picked this morning, so make sure you check your inboxes! But if you weren’t selected, have no fear. I’ll be announcing something even bigger to help even more job seekers in need of LinkedIn mentorship soon, so stay tuned!

If you’ve followed me on LinkedIn for at least a year now, you probably knew me for the SQL tips I used to share.
The “did you know about this cool SQL trick?” posts with colorful graphics I made in Carbon were such a hit on LinkedIn, so I thought I’d bring back my biggest hits!
1. QUALIFY clause

QUALIFY allows you to filter the results of window functions, and basically does to window functions what HAVING does to aggregate functions.
To be able to QUALIFY a query, you can either use a window function in the QUALIFY clause or you can use it to reference a window function used in your SELECT list.
As a result, you can avoid the complicated subqueries and CTEs that are normally required if you want to filter based on a window function!
**This is only available in BigQuery, Teradata, Snowflake and Databricks.
2. Getting the first record of a non-numeric column

While you can use MIN and MAX to retrieve the first record in numeric and timestamp columns, using CONCAT + LTRIM is how we’ll do so for other columns.
By concatenating the column we care about with the timestamp column, we can still use MIN() to retrieve the first time-based record. Then we can trim away the time so that we’re left with just the attribute of interest.
With this nifty trick, we end up with a much faster query that works just within the SELECT clause, so we can use a GROUP BY on it 👌
3. USING clause

USING allows you to specify your join key only once instead of twice in an expression of equality as you would using ON.
Another perk is the column(s) you’ve selected are only output once! No more ambiguous duplicate columns like id1, id2, id3, etc.
**This clause isn’t available for SQL Server.
4. Wildcard tables

Wildcard tables allow you to union tables with similar names and query them all at once.
All you need in your wildcard table name is the special character (*), with its name enclosed in backtick characters (`) to represent the naming pattern of all the tables you want to union together. Then you can query from that new wildcard table as if it’s just one big table.
**This one is only available in BigQuery.
5. Lateral column alias referencing

If you’ve ever come across the frustrating error message “Invalid column name…” after you’ve created an aliased column in your SELECT statement, then tried to reuse that alias elsewhere in your query, this trick is for you.
Lateral alias referencing allows you to reuse an alias within a query as soon as it’s declared, meaning you don’t have to repeat the expression from your SELECT clause.
**This is only available in Redshift, Snowflake, BigQuery and Teradata.
6. CASE WHEN for pivoting

You can certainly use the PIVOT function when you need to turn unique values in a column into individual columns, but the syntax for it has always been so hard to remember for me.
Pivoting using CASE aggregates by the column for which you want to get unique values, and then defines the scenarios that would classify a given record to each of those values.
7. LISTAGG

The LISTAGG function allows you to concatenate strings from multiple rows into a single row, and can be used in both aggregate and window functions. And when you add in a DISTINCT in the function, you get a list of unique values!
**This only works in Oracle, Snowflake and Redshift. The equivalent in MySQL is GROUP_CONCAT and STRING_AGG in BigQuery and SQL Server.
8. Column exclusion in SELECT statement
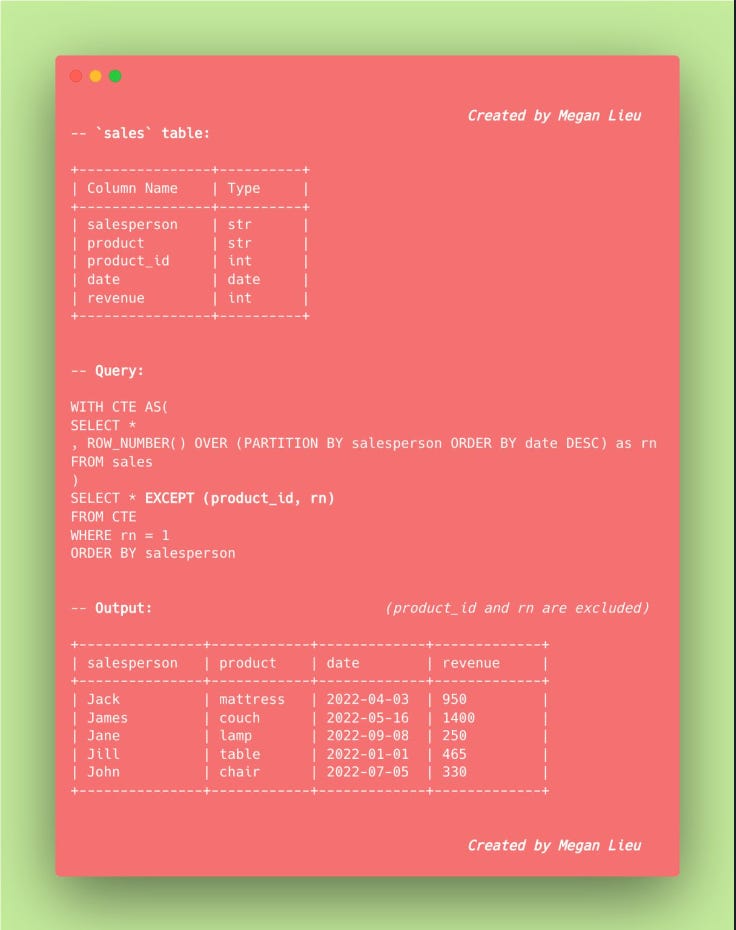
When joining two tables, instead of specifying all the columns except the one you want, you can simply use SELECT * EXCEPT to save plenty of lines of code.
**This only works in BigQuery and Databricks.
9. Natural joins

Natural joins eliminate the need to type out any join expression or join columns, but the caveat is that all joining columns you use need to have the same name. That means you must do your due diligence beforehand to make sure you know of all the columns that will be used to naturally join your tables.
**This doesn’t work in SQL Server.
That’s it for this week’s newsletter! See you for the next episode of The Data Diaries soon 👋
- Megan
And in case you don’t know who I am, I’m Megan Lieu, Data Scientist-turned-Developer Advocate who has helped thousands of job seekers through my content on LinkedIn and Instagram, as well as my courses on LinkedIn Learning. I’ve learned a lot from the ups and downs of my data career, and sharing the lessons has helped me build a community of 180k+ tech and data professionals.
Great tips! Not familiar with some of these.
wowwwwwwwww